
Use cases
The user from either the PUNCH community or from other science communities is in the focus of the NFDI efforts. The consortium collected in a real bottom up approach initially nearly 100 different use cases from all participating Physics communities. According to their main focus they were categorised into distinct classes that allowed the definition of PUNCH-overarching tasks and deliverables. The process leading from use cases to concrete deliverables (later grouped into task areas) is shown in the figure below.
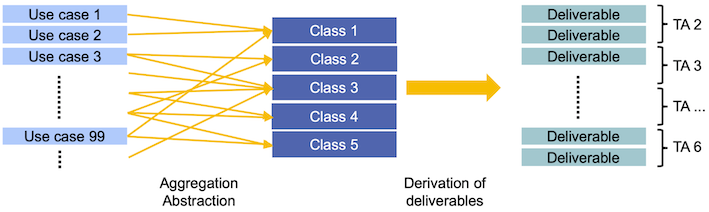
The currently 6 use case classes are:
- Validating and publishing scientific data collections
- Analysis of local or distributed data sets
- Execution of analysis of numerical simulations
- Community-overarching data challenges
- Real-time challenges & data irreversibility
- Use cases from external partners
are described below. Details about individual use cases can be found by clicking on the titles. Corresponding user stories exemplifying this case can be found by clicking on the pictures next the use case descriptions.
Use case class 1: Validating and publishing scientific data collections
Scientific data collections produced by individuals or science collaborations are more valuable when made available to the broader community in a manner consistent with the FAIR principles. Doing so requires efficient tools for making the data accessible through standard protocols for selection and retrieval. Support is also needed for metadata provision, minting DOIs, etc. Furthermore, infrastructure is needed to create workflows that can be used for vetting such data for publication and subsequent analysis. The availability of these data collections would then enable new cross-experiment/cross-collaboration data sharing, ultimately leading to new scientific discoveries.

Use case class 2: analysis of local or distributed data sets
Analysing distributed or local data sets consitutes a core element of the scientific enterprise and for this it is essential to deploy a data management system that enables data finding, efficient data movement, and the execution of compute jobs. It is also crucial for users to be able to control and monitor these analyses through a uniform portal interface. Three types of analyses needs to be supported: downloading intermediate data sets from an archive to a local compute platform, moving the data to a large scale shared compute resource, extremely large datasets where the so-called code-to data approach needs to be adopted. The PUNCH4NFDI science portal will provide a working solution for PUNCH and other communities.
Use case class 3: execution of analysis of numerical simulations
Numerical simulations play a fundamental role in the interpretation of experimental data. The production of these data is computationally expensive and often large quantities of data are produced, Therefore, additional structures and tools are needed to support the optimised use of simulation data and to enable the accessibility and analysis of these simulations through a common set of tools. PUNCH will provide several actions that will optimise the performance of the most commonly used codes and will moreover provide easy-to-use tools that will allow an easy publication of the data which requires also the development of corresponding metadata standards.
Use case class 4: community-overarching data challenges
A large amount of research data of different origin and without a common structure is produced by experimental and theoretical groups. These data are often useful in further scientific studies, but in many cases are not available within a FAIR context. A cross experiment analysis with combined data sets would allow to reduce systematic uncertainties and has the potential to provide new physical insights. The main challenge in realizing this use case is then to make such preprocessed data sets available in a format that will enable a common analysis. PUNCH4NFDI will provide interfaces and corresponding physics models.

Use case class 5: real-time challenges, data irreversibility
In experiments of high-energy physics and upcoming astronomical observatories, data are taken at rates much too high to be storable in long-term archives. This use case class addresses the challenge of extracting in real-time the tiny subset of ”interesting data” out of huge data streams in an automated way. The tools and methods currently used are not sufficient to cope with future demands. PUNCH4NFDI will develop methods for coping with the challenges due to ”data irreversibility”, as decisions on what part of the incoming data streams need to be rejected have to be taken in real-time and the unavoidable resulting loss of information is mostly not reversible.

During the preparations of the PUNCH4NFDI marketplace of task area 6
“Synergies and services”, a number of collaborations with other NFDI consortia
started to emerge. Some of them are interested in using PUNCH infrastructure, namely the
PUNCH science data platform PUNCH-SDP for solving their own computational questions.
In such cases, these consortia provided their use case to PUNCH so that the necessary
adjustments, if needed, can be done in collaborative work.
